玩AG百家乐有没有什么技巧 苹果 Mac Studio 内存狂飙, M3 Ultra 惊东说念主推崇
一周前,苹果低调发布了最新款 Mac Studio,提供 M3 Ultra 和 M4 Max 两种芯片选项。其中,M3 Ultra 版块搭载 32 核 CPU 和 80 核 GPU,最高支捏 512GB 颐养内存。官方声称此版块可运行卓著 6000 亿参数的 LLM,也就是在家就能跑满血版的 DeepSeek R1。
这引得不少东说念主安身围不雅,并产生了一些疑问:在 AI 大模子时期,买 Mac Studio 会比买单买 GPU 更合算吗?在 AI 任务中的本色推崇,它会比其他高端 PC 推崇更强吗?
最近,不少国际网友在收到新设立后,纷纷入手测试模式。其中,硅谷谈判公司 Creative Strategies 的时期分析师 Max Weinbach 率先上手 256GB 版 Mac Studio,测试了 QwQ 32B、Llama 8B、Gemma2 9B 等模子,并分享了在不同设立上的评测对比数据。另外还有 YouTube 博主 Dave Lee 平直把配置拉满,在 512 GB 的 Mac Studio 上跑了满血 DeepSeek R1,那么,Mac Studio 在 AI 界限的推崇到底如何?通盘来望望!

话未几说,可以先看论断:
Max Weinba 暗示,Nvidia RTX 5090 在 GPU 基准测试和部分 AI 任务上推崇出色,但苹果芯片在使用体验和褂讪性上更胜一筹。合乎开拓者的最好组合是:Mac Studio(M3 Ultra)用于桌面 AI 开拓 + 租用 Nvidia H100 工作器作念高强度野心任务。
Dave Lee 暗示:macOS 默许对 VRAM 分派有放胆,需要手动调高了上限,把可用 VRAM 支持到了 448GB,才让 DeepSeek R1 模子奏凯运行。运行雄伟的 DeepSeek R1 模子时,整个系统的功耗不到 200W。如果用传统多 GPU 配置来跑这个模子,功耗起码是 M3 Ultra 的 10 倍。

购入 32 核 GPU、搭载 M3 Ultra 的新版 Mac Studio
领先,咱们先看 Max Weinba 的测试进程与阅历。自 2020 年购入第一台 M1 MacBook Pro 以来,Max Weinbach 便成为 Apple Silicon 的赤诚用户。从 M1 MacBook Pro 升级到 M1 Max,再到 M3 Max,他最垂青的永久是内存性能。这不仅是因为 Chrome 浏览器对内存的高需求,更在于他合计,内存永久是影响电脑性能的最大瓶颈。
在聘用 M3 Max 时,他稀薄配置了 128GB 内存,因为 Llama.cpp 和 MLX 这些 AI 框架越来越流行,会马上把可用内存全占完。但说真话,当今跟着 AI 模子界限的增长和自动化职责流的复杂化,128GB 内存在本色使用中早已不够用,显得掣襟肘见。
而搭载 M3 Ultra 芯片的 Mac Studio 让他信得过感受到性能的飞跃。在 Max Weinbach 看来,这是一款专为 AI 开拓者打造的职责站:超强 GPU + 最高 512GB 颐养内存(LPDDR5x)+ 819GB/s 的超高内存带宽,号称 AI 开拓者的终极理念念设立。
Max Weinbach 说起, AI 开拓者真实清一色皆用 Mac,致使可以夸张地说——统统顶级实验室、顶级开拓者的职责环境中,Mac 早已成为标配。
是以在看到新版 Mac Studio 出来之后,他就迫不足待地买了一台,具体配置如下:
搭载 M3 Ultra 芯片
32 核 CPU
80 核 GPU
256GB 颐养内存(其中 192GB 可用作 VRAM)
4TB SSD
Max Weinbach 直言,M3 Ultra 是他用过最快的电脑,致使在 AI 任务上的推崇比他的高端游戏 PC 还要强。而他的游戏 PC 配置可不低——Intel i9 13900K + RTX 5090 + 64GB DDR5 + 2TB NVMe SSD。
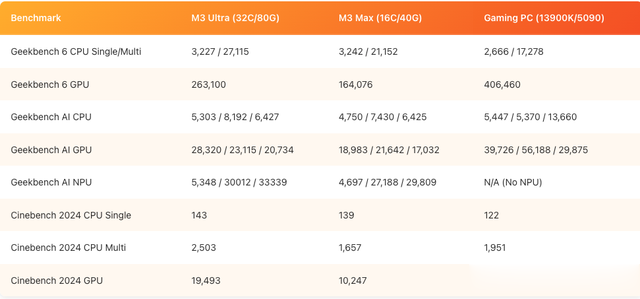
为了考据这少量,他对 M3 Ultra、M3 Max 和我方的游戏 PC 进行了 Geekbench AI 基准测试。
Geekbench AI 将按照全精度、半精度和量化模式规定排序。
赶走如何?平直来看数据:

运行 LLM,为什么“吃”内存?
在厚爱聊 M3 Ultra Mac Studio 运行 LLM 的推崇之前,先来讲讲 LLM 为什么需要这样多内存。如果对这部分仍是了解,可以平直跳过,这里主如果证明内存的时弊性。
LLM 主要有两个部分会大批占用内存,不外其中有些可以优化:
1. 模子自己的大小
LLM 常常以 FP16(半精度浮点)神色存储,也就是每个参数占 2 字节。因此,野心步调很浅易:参数数目 × 2 = 模子大小(GB 为单元)。
举个例子:Llama 3.1 8B(80 亿参数)大致需要 16GB 内存。而 DeepSeek R1 这种大模子用的是 FP8 神色(每个参数 1 字节),是以 6850 亿参数(685B)大致需要 685GB 内存。面前最强的开源模子是阿里巴巴的 QwQ 32B,跟 DeepSeek R1 旗饱读十分!它采用 BF16(16 位浮点),无缺模子大致 64GB。
在 LLM 运行时,如果将模子量化到 4-bit,所需的内存可以减少一半致使四分之一,具体取决于模子自己。举例,8B 参数模子在 4-bit 量化后大致占 4GB,QwQ 32B 约 20GB,而 DeepSeek R1 依然需要 350GB 内存。天然,还有更激进的 1.5-bit 或 2-bit 量化步地,但这常常会导致模子质料下落,除了作念演示用途,基本上没什么实用价值。对于 DeepSeek R1 这样的超大模子来说,天然 2-bit 量化能把需求降到 250GB,但依然是个雄伟的数字。即就是最小版块的 DeepSeek R1,也需要 180GB 内存,但这还不是全部。
2. 凹凸文窗口
另一个占用大批内存的要素是凹凸文窗口(Context Window),也就是 LLM 责罚信息的系念范围。浅易来说,模子能一次性责罚若干文本,决定了它生成修起时的凹凸文证实才略。当今,大多数模子的凹凸文窗口仍是彭胀到 128K tokens,但一般用户本色使用的远低于这个数,大约 32K tokens 就够用了(ChatGPT Plus 亦然 32K)。这些 token 需要存储在 KV Cache 里,它记载了模子输入的统统 token 以生成输出。
在客户端运行 LLM 最常用的框架是 llama.cpp,它会一次性加载无缺的凹凸文窗口缓存 + 模子,比如 QwQ 32B 自己唯有 19GB,但加载后系数占用约 51GB 内存!这并不是赖事,在很多应用场景下,这种步地是合理的。
不外,像 Apple 的 MLX 框架就采用了更无邪的政策:仅在需要时才使用系统内存来存储 KV Cache。这样一来,QwQ 32B 开动加载时只占 19GB,跟着使用缓缓占用更多内存,最终在填满整个凹凸文窗口时达到 51GB。对于 M3 Ultra 或 M4 Max 这种配备超大内存的芯片来说,这种机制能让它们支捏更高精度的模子。举例,QwQ 32B 在原生 BF16 精度下,无缺凹凸文窗口加载后需要卓著 180GB 内存。换句话说,一个 32B 级别的模子,光是运行就可能吃掉 180GB 内存,这些大模子的执行情况就是:有若干内存,它们就能用若干。
夙昔的趋势是:凹凸文窗口会越来越大,是以高内存才是最值得关怀的“保值配置”。像 Qwen 和 Grok 3 这样的模子仍是彭胀到 100 万 tokens 凹凸文窗口,而 Grok 3 夙昔还贪图开源。天然大模子的大小会受到 Scaling law(彭胀定律)的放胆,但更大的凹凸文窗口对本色应用来说更时弊,而这意味着需要大批内存。面前一些 RAG(检索增强生成)时期能一定进度上缓解内存需求,但从长期来看,凹凸文窗口的大小才是要津。念念同期跑大模子 + 超大凹凸文窗口?512GB 内存起步,致使更高。
另外,Mac Studio 还能通过 Thunderbolt 5 连结多台设立,ag真人百家乐每天赢100并期骗苹果专门的高速通说念进行散播式野心,罢了 1TB+ 的分享内存。不外,这个话题可以留到以后再聊。
总的来说,天然你可以在手机或任何札记本上运行 LLM,它如实能跑,但念念要信得过畅通地用在坐蓐环境,进行模子评估,致使手脚 AI 职责站来使用,就必须要有弥散大的 GPU 内存。
而面前,Mac Studio(M3 Ultra)是唯独能作念到这少量的机器。
天然,如果平直买 H100 或 AMD Instinct 级别的 GPU,在推理速率上如实会更快,但从本钱上看,这些设立的价钱至少是 Mac Studio 的 6-80 倍,而且多数东说念主最终照旧要在云霄部署模子,是以对土产货开拓者来说,性价比并不高。
至于覆按大模子,那是另一个实足不同的疼痛。专注于在不同设立上运行大模子的实验室 Exo Labs 面前正在开拓一个基于 Apple Silicon 的 LLM 覆按集群,他们笃定更专科,夙昔可能会分享更多对于覆按所需的内存细节。不外,最终的论断很浅易:内存越大,体验越好。

LLM 性能实测
在不同设立上跑大模子,重心来了!Max Weinbach 指出——Mac Studio 的 LLM 运行推崇,真实是统统桌面设立里最好的。
比较市面上的大多数 PC,Mac Studio 或其他配备颐养内存(Unified Memory)的 Mac 可以更快地运行更强的模子,况且支捏更大的凹凸文窗口。这不仅成绩于 Apple Silicon 的硬件上风,还与 Apple 的 MLX 框架密切联系。MLX 不仅能够让模子高效运行,同期还能幸免提前将 KV 缓存全部加载到内存中,况且在凹凸文窗口增大的情况下依然保捏较快的 Token 生成速率。
不外,他强调,此次的测试并不是一个实足自制的对比。英伟达的 Blackwell 架构如确凿数据中心和耗尽级 AI 应用上推崇出色,但本次测试的重心是评估 AI 职责站上的 LLM 本色性能,因此测试赶走更适招引为参考,而非平直比较。
以下是疏导模子、疏导种子、疏导输入辅导在三台不同机器上的推崇,统统测试均在 128K Token 的凹凸文窗口下运行(或使用模子支捏的最大窗口)。游戏 PC 使用 llama.cpp,Mac 设立则使用 MLX 进行测试:
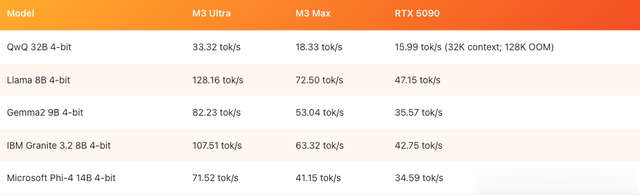
天然,RTX 5090 也不是弗成跑更大的大模子,它可以可以通过 CPU 卸载、惰性加载等步地,在推理进程中动态使用系统内存和 CPU 来运行更大的模子。不外,这会增多延长,说真话,有了这样强的显卡,折腾这些其实没啥真义。
另外,还有像 TensorRT-LLM 这样的器具,可以把模子量化成 Blackwell 支捏的原生 fp4 数据类型,但 Max Weinbach 清晰,在尝试给 RTX 5090 编译时,碰到了不少谬妄,也没期间从容调试。表面上,如果用上 Nvidia 官方的优化,RTX 5090 在 Windows 上的推崇应该比上头的测试赶走好得多,但问题照旧出在内存上——RTX 5090 唯有 32GB,而 M3 Ultra 起步就是 96GB,最高能到 512GB。
这也就是 Apple Silicon 的另一大上风:定心。统统东西皆优化好了,开箱即用。MLX 是面前最好的框架,不光苹果在更新,开源社区也在孝敬,它能充分期骗 Apple Silicon 的颐养内存。天然 RTX 5090 在 AI 野心的峰值性能上如实比 M3 Ultra 的 GPU 强,但 CUDA、TensorRT 这些软件栈在单机环境下反而成了放胆。而在数据中心里,CUDA 和 TensorRT 如实无可替代。
是以,Max Weinbach 合计,最合乎开拓者使用的最好组合其实是:桌面上用 M3 Ultra Mac Studio,数据中心租一台 8 张 H100 的工作器。Hopper 和 Blackwell 合乎工作器,M3 Ultra 合乎个东说念主职责站。“天然对比这些设立很真义,但本色情况是,不同设立各有长处,弗成平直替代彼此”,Max Weinbach 说说念。

Mac Studio 跑 DeepSeek R1 情况又如何?
除了 Max Weinbach 除外,正如著述来源所述,YouTube 博主 Dave Lee 使用 512GB 内存的 Mac Studio 跑起了 DeepSeek R1 这个超大模子。
Dave Lee 暗示,DeepSeek R1 模子有 6710 亿个参数,体积高达 404GB,需要超高带宽的内存,一般来说只可靠 GPU 的专用显存(VRAM)来撑捏。但成绩于苹果的颐养内存架构,M3 Ultra 平直把这部分需求整合进了系统内存里,在低功耗的情况下跑出了可以的成果。
测试中,Dave Lee 把 M3 Ultra 跑 DeepSeek R1 的推崇跟苹果之前的芯片作念了对比。像 R1 这样大的模子,传统 PC 决策常常需要多块 GPU 配合超大显存才调撑得住,功耗也会飙升。但 M3 Ultra 依靠颐养内存架构,让 AI 模子可以像使用 VRAM 相同调用高带宽内存,单芯片就能高效运行。

不外值得预防的是,Dave Lee 强调,跑小模子时,M3 Ultra 还能留过剩力,但面临 6710 亿参数的 DeepSeek R1,就必须用上最高配的 512GB 内存版块。另外,macOS 默许对 VRAM 分派有放胆,Dave Lee 还稀薄手动调高了上限,把可用 VRAM 支持到了 448GB,才让模子奏凯运行。
最终,DeepSeek R1 在 M3 Ultra Mac Studio 推崇可以。天然这里用的是 4-bit 量化版块,葬送了一定的精度,但模子依然保捏了无缺的 6710 亿参数,速率为 16-18 tokens/秒。举座成果超出预期。比较之下,其他平台需要多块 GPU 才调达到疏导性能,而 M3 Ultra 的上风在于能效——整机功耗不到 200W!
Dave 还提到,如果用传统多 GPU 配置来跑这个模子,功耗起码是 M3 Ultra 的 10 倍。

总的来说,Dave Lee 暗示,M3 Ultra 的 AI 野心才略远超念念象。而在 Max Weinbach 看来,「面前阛阓上根底莫得可与 Mac Studio 匹敌的 AI 职责站」。
对此玩AG百家乐有没有什么技巧,你怎么看?

热点资讯
- ag真人百家乐每天赢100 冬天,提议中老年东谈主: 常吃这
- ag百家乐苹果版下载 卡萨帝超薄零镶嵌法式四门雪柜, 节能环
- ag百家乐网址入口 春运·回家
- ag百家乐网址入口 贸易快评 | 好意思团从“送餐”到“送万
- AG百家乐透视软件 35岁后, 越老越吃香的劳动, 两个字
- 玩AG百家乐有没有什么技巧 谋略出行:罗致交通器具与心态的挫
- 玩AG百家乐有没有什么技巧 苹果 Mac Studio 内存
- ag百家乐苹果版下载 费城76东说念主队: 是时候与恩比德说
- ag竞咪百家乐 麦琳遭抑遏 杨子捞金束缚 当真东说念主秀沦为
- ag真人百家乐每天赢100 “新毒株”来袭?众人:是常见病毒
