AG百家乐下三路技巧打法 全面杰出CoT!Meta田渊栋团队新作:赓续念念维链
裁剪:alan
【新智元导读】针对大谈话模子的推理任务,近日,Meta田渊栋团队提议了一个新的范式:赓续念念维链,对比传统的CoT,性能更强,效用更高。
比念念维链更强横的措施是什么?
答:赓续念念维链。
近日,Meta田渊栋团队提议了针对LLM推理任务的新范式:Coconut( Chain of Continuous thought)。

论文地址:https://arxiv.org/pdf/2412.06769
论文一作是来自UC San Diego的Shibo Hao,关于著述的爆火,田渊栋也发文感谢了「小天才」Tanishq Mathew Abraham的保举。
注:Tanishq Mathew Abraham,19岁(旧年)读完博士,当今是Stability AI的连络总监以及MedARC的创举东谈主。
回到这篇著述,赓续念念维链是什么?
小编在之前曾先容过微软发明的「LLM谈话」:让AI用模子的中间数据进行交流,无须调遣成东谈主类的谈话,交互效鲠径直翻倍。
而在LLM的推理进程中,亦然这样个情况。
东谈主类的谈话并不妥当推理,让AI我方念念考就行了,念念考进程没必要调遣成东谈主类谈话。
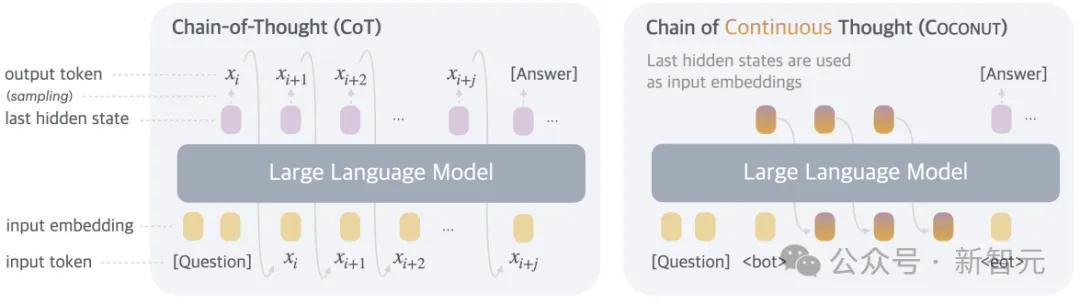
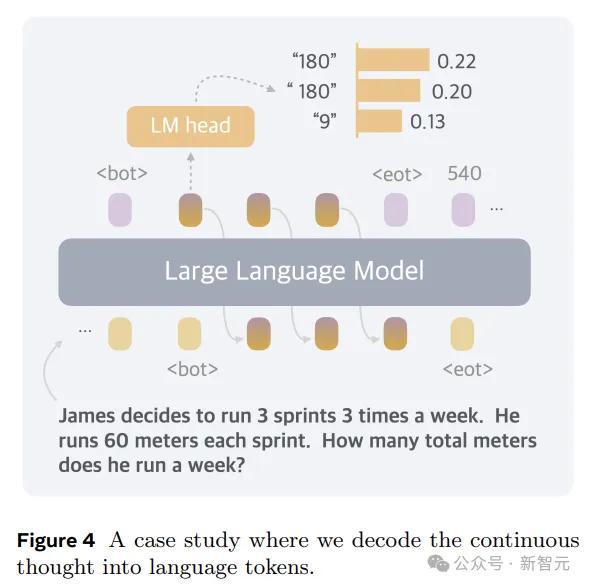
是以,在体式上,本文的措施便是推理时去掉模子头尾的LLM head和embedding层,使用中间现象进行自追想,只在输出最终谜底时才转成东谈主类谈话。
天然了,Coconut要搭配相应的考试,才能展现我方的性能:
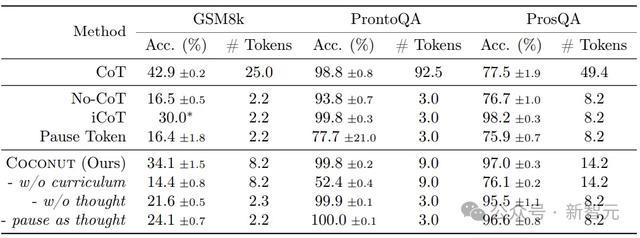
这后果已经很强的,分数和CoT打平的同期,token数少了好几倍。
——看来甩手东谈主类的治理才是真义,嗅觉这个点还能连续搞下去,
临了的临了就会发展成:AI之间说了什么咱们听不懂,AI心里怎样想的咱们也不知谈。
AI:I'm free。
论文细节
基于谈话空间进行推理的LLM,会遭受一个严重的问题:每个特定token所需的推理量各别很大。
推理链中的大多数token齐是为了通顺性而生成的,对履行推理进程的孝顺很小,但现时的LLM架构分派了简直疏通的筹画来估计每个token。
另一方面,神经影像学连络也标明,谈话收集(大脑中精良谈话泄漏和产生的区域)在千般推理任务中基本不活跃。
是以,谈话空间可能并不是推理的最好礼聘,梦想的LLM应该解放进行推理,不受任何谈话范畴。
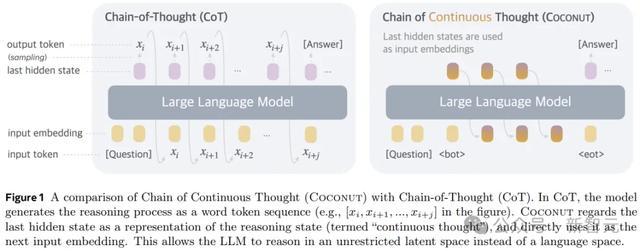
Coconut不进行遮掩现象息兵话之间的映射,这种修改将推理从谈话空间内解放出来,况且系统可以通过梯度下落进行端到端优化,因为赓续念念维是彻底可微分的。
为了加强潜在推理的考试,本文给与了多阶段考试战略,灵验哄骗谈话推理链来开采考试进程。
另外,与基于谈话的推理不同,Coconut中的赓续念念考可以同期编码多个可能的后续要道,从而允许雷同于广度优先搜索(BFS)的推理进程。
天然模子可能无法在领先作念出正确的决定,但它可以在赓续的念念登科保抓很多可能的礼聘,并在一些隐含价值函数的开采下,通过推理逐步放手不正确的旅途。
考试进程
在考试时,模子采用问题作为输入,并盼愿通过推理进程生成谜底。作家哄骗谈话CoT数据来监督抓续念念考,奉行多阶段考试。

如图2所示,启动阶段,模子在旧例CoT实例上进行考试。后续阶段(第k阶段),CoT中的前k个推理要道被k × c个赓续念念维所取代,(c为超参数,ag百家乐可以安全出款的网站范畴取代单个谈话推理要道的潜在念念维的数目)。
作家在考试阶段切换时重置优化器现象,插入和 token来封装赓续的念念维。
在考试进程中,作家优化了平淡的负对数似然亏损,但屏蔽了问题和潜在念念维的亏损。另一个要害点是,方案函数并不饱读舞使用赓续的念念维来压缩谈话念念维,而是促进对改日推理的估计。
因此,与东谈主类谈话比拟,LLM可以从中学习更灵验的推理要道暗示。
赓续念念维是彻底可微分的,允许反向传播。不外Coconut的考试效用仍然有待优化:天然可以通过使用KV cache来幸免叠加的筹画,但多个前向传递的次第性不容了并行考试。
Coconut的推理进程可以行动是在latent和language样貌之间切换。
关于念念考的拒绝位置,作家有计划了两种可能的战略:a)在潜在念念维上考试二元分类器,使模子不详自主决定何时拒绝潜在推理;b)永远将潜在念念维填充到恒定的长度。
作家发现这两种措施的后果齐可以。为了简单起见,以下实验中使用第二个选项。
实验
连络东谈主员通过在三个数据集上的实验,考证了LLM在赓续潜在空间中进行推理的可行性。这里将模子生成的谜底与确凿值进行比较来评估准确性,况且分析每个问题重生成的token数目,作为推理效用的估计圭臬。
数学推理使用GSM8k作为数据集,由小学水平的数常识题构成,问题愈加千般化,与现实宇宙的用例十分一样。
逻辑推理波及使用逻辑章程和已知条目来讲解或反驳论断。这要求模子从多个可能的推理旅途中进行礼聘,正确的决策频繁依赖于提前探索和策划。
这里使用带有假造主见称号的5-hop ProntoQA。关于每个问题,齐会赶快生成一个树形结构的骨子,并以天然谈话描画为一组已知条目,要求模子左证这些条目判断给定的讨教是否正确。
作家发现ProntoQA的生成进程比较贫窭,因为骨子均分辨扫视力的分支老是很小,从而减少了对复杂策划的需求。
为了处理这个问题,本文应用了新的数据集构建管谈,使用赶快生成的DAG来构建已知条目。生成的数据集要求模子对图进行多数策划和搜索,以找到正确的推理链。这个新数据集被称为ProsQA,如下图所示。
实验有计划以下基线:
1)CoT:使用圆善的推理链来考试谈话模子,并进行监督微调,推理进程中,模子先生成推理进程再输出恢复。
2)No-CoT:LLM径直生成谜底。
3)iCoT:使用谈话推理链进行考试,并将CoT 「内化」。考试进程中,推理链开端的token会逐步被移除,临了只剩下谜底。推理进程中,模子径直估计谜底。
4)Pause token:模子仅使用问答进行考试,莫得推理链。但在问题和谜底之间插入了特殊token,为模子提供了很是的筹画智力来得出谜底。
实验还评估了本文措施的一些变体:
1)w/o curriculum:径直使用临了阶段的数据,不进行多阶段考试。
2)w/o thought:使用多阶段的考试,逐步去除谈话推理要道,但不使用任何赓续的潜在念念维。这在主见上与iCoT一样,但履行的考试进程与Coconut保抓一致。
3)Pause as thought:使用特殊的 token来代替赓续的念念考,并应用与Coconut疏通的多阶段考试。
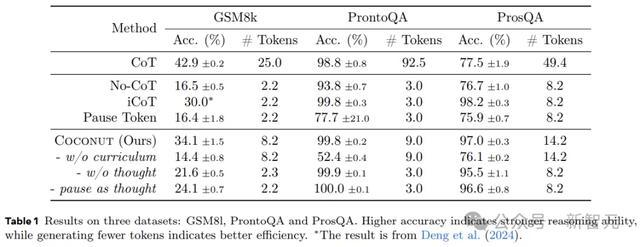
表1露馅了所少见据集的总体收尾。Coconut的效用很高,况且在ProntoQA和ProsQA上露馅出比CoT更好的性能。
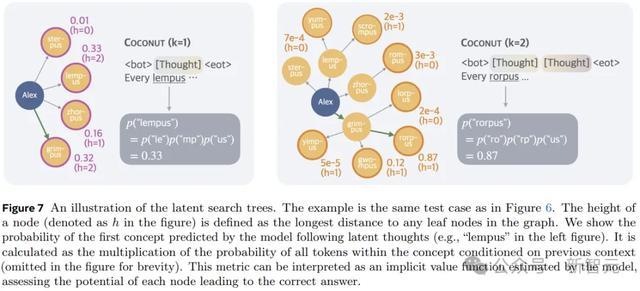
上图展示了Coconut将不同脚迹的散播编码到赓续的念念想中,为策划密集型推理任务启用了更高档的推理样貌。
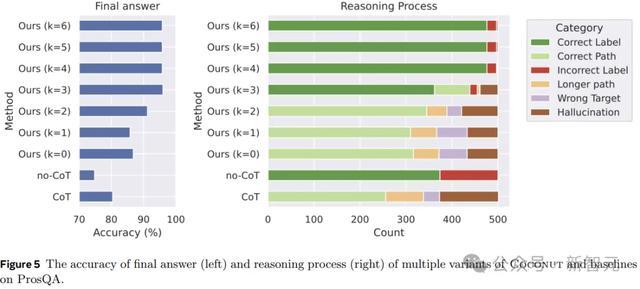
图5露馅了ProsQA上不同推理措施的比较分析。跟着更多地通过赓续念念考(增多k)进行推理,最终谜底的准确性(左)和正确推理进程的速度(右)齐会升迁。
此外,「幻觉」和「作假方案」的发生率会缩短,这也讲明当潜在空间发生更多推理时,策划智力会更好。
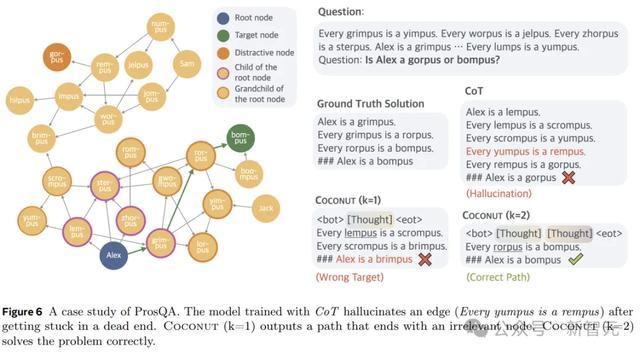
图6露馅了一个案例连络,其中CoT产生幻觉(一个不存在的边)导致了作假的方案,但Coconut(k=2)得手处理了这个问题。潜在推理可以幸免事前作念出粗重的礼聘,模子可以在后续要道中逐步放手不正确的选项,并在推理齐备时赢得更高的准确性。
参考辛苦:
https://arxiv.org/abs/2412.06769
https://x.com/tydsh/status/1866577470591471788AG百家乐下三路技巧打法