 ag百家乐赢了100多万
ag百家乐赢了100多万
芝能智芯出品
生成式东谈主工智能(GenAI)的快速发展正在深刻改变芯片联想的需求模式,对筹划智商、架构联想和封装技艺提议了前所未有的挑战。
Synopsys 近期举办的一场相聚研讨会,深入探讨了先进 AI 芯片的 IP 条目,GenAI 怎样鼓吹芯片技艺向更高性能、更复杂架构的标的演进。
往时五六年中,GenAI 对筹划智商的需求激增了一万多倍,促使 SoC 联想从单片转向多芯片架构,鼓吹了先进封装技艺、高带宽内存(HBM)和芯片间通讯的更动。
咱们将详备分析 GenAI 对芯片联想的影响,并探讨 Synopsys 提议的三项要津技艺科罚有筹画:芯片间通讯、定制 HBM 和 3D 堆叠。

Part 1
生成式东谈主工智能
对芯片联想的影响
生成式东谈主工智能的崛起极地面提高了对筹划智商的需求。以当然话语处理(NLP)领域的模子为例,从早期的 GPT-3 到如今的 GPT-4 和 Megatron-Turing NLG,模子参数范围赶快扩大,筹划需求呈指数级增长。
往时五六年间,GenAI 的筹划需求增长了 10,000 多倍, AI 应用对芯片性能的极高条目,迫使芯片联想者阻抑传统技艺遣散,缔造好像支撑超大范围并行筹划的芯片。
需求的增长不仅体当今筹划中枢的数目上,还体当今对数据抵赖量和能效的更高条目。举例,磨真金不怕火一个大型话语模子可能需要数千个 GPU 或 TPU 并走运转数月,消费的筹划资源远远杰出传统应用,芯片联想必须在制程工艺、架构优化和功耗管制上兑现全面提高。

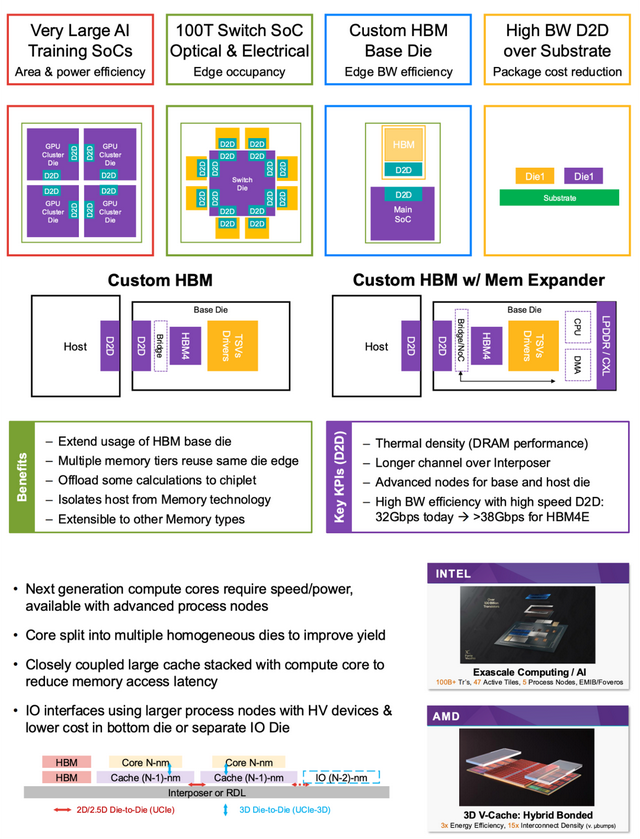
传统单片 SoC(片上系统)将扫数功能模块集成于单一芯片,具有联想肤浅、老本较低的上风,晶体管数目阻抑万亿级,单片联想靠近诸多挑战:先进制程节点的良率下落、功耗过高以及散热发愤等问题日益突显。
GenAI 的筹划需求鼓吹了 SoC 联想从单片向多芯片架构的蜕变。多芯片 SoC 通过将功能模块阐明到多个独处芯片(chiplet),哄骗高速芯片波折口兑现协同职责。
这种架构的上风在于无邪性和性能优化。筹划中枢可接纳 3nm 或 5nm 等先进制程以提高性能,而 I/O 或内存模块则可使用更熟识的 28nm 或 16nm 工艺以诽谤老本。
此外,多芯片联想还能灵验缓闭幕热问题,通过分辩热源提高全体系统的清爽性。
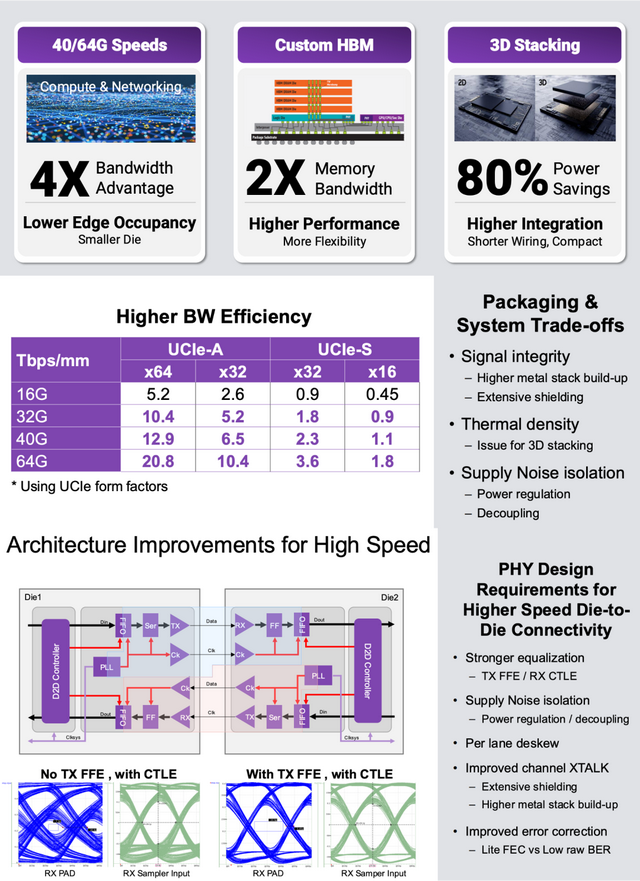
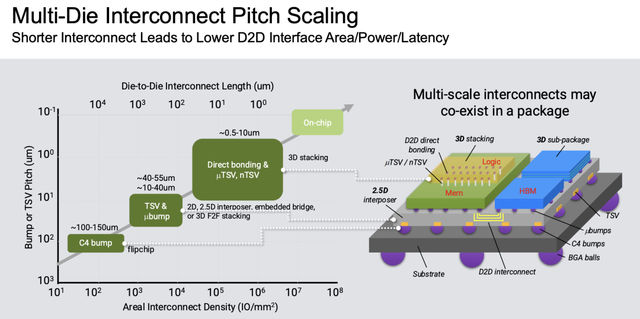
跟着芯片功能的增多和筹划需求的提高,芯片范围连续扩大,传统 2D 封装技艺已难以得志需求,先进封装技艺正在从 2D、2.5D 向 3D 和 3.5D 演进。
从头散播层(RDL)中介层技艺通过跨越多个掩模版兑现高密度互连,成为科罚芯片范围问题的膺惩技能。
◎ 2.5D 封装哄骗硅中介层将多个芯片比肩舍弃,提供更高的带宽和集成度。
◎ 而 3D 封装通过垂直堆叠芯片,进一步镌汰了信号旅途,诽谤了蔓延和功耗。
这种技艺的应用在 GenAI 驱动的高性能 SoC 中尤为要津,好像支撑更大范围的筹划单位和内存模块集成。
GenAI 对内存带宽和容量的需求相似显赫,鼓吹了内存架构的创新。
高带宽内存(HBM)技艺成为得志这一需求的中枢科罚有筹画。通过堆叠多层 DRAM,HBM 好像在有限的空间内提供极高的带宽,举例 HBM3 的单堆栈带宽可达 2TB/s 以上。
相聚研讨会止境提到,定制 HBM(cHBM)通过在基础芯片上集成逻辑工艺,进一步提高了内存架构的无邪性和性能。
内存堆叠技艺的应用使得 SoC 好像更高效地处理 GenAI 任务中的大范围数据集。举例,在磨真金不怕火深度神经相聚时,芯片需要快速看望无边参数和中间遣散,HBM 的高带宽和低蔓延秉性显赫提高了数据抵赖量。
多芯片 SoC 的普及使得芯片间通讯带宽成为系统性能的要津瓶颈,芯片间带宽正从 16Gbps/pin 提高至 32Gbps/pin,甚而达到 64Gbps/pin。
高速接口表率如 UCIe(Universal Chiplet Interconnect Express)应时而生,为芯片间通讯提供了搭伙范例。
Synopsys 的 64Gbps 芯片间通讯 IP 科罚有筹画在这一领域证据隆起,不仅支撑高数据速率,还具备低功耗模式和凡俗的可测试性功能。这种技艺的杰出确保了多芯片 SoC 好像高效协同职责,得志 GenAI 对带宽和低蔓延的尖酸条目。
Part 2
要津技艺阐明
● 芯片间通讯
芯片间通讯是多芯片 SoC 的中枢技艺,径直决定了系统的全体性能,Synopsys 的 64Gbps 芯片间通讯 IP 科罚有筹画。
该有筹画针对专属系统进行了优化,具有以下秉性:
◎ 高数据速率:支撑高达 64Gbps/pin 的传输速率,AG百家乐计划相较于 16Gbps/pin 的传统接口,带宽提高了 4 倍。
◎ 低功耗联想:提供低功耗模式和可转换旋钮,稳妥不同应用场景的能效需求。
◎ 可靠性与可测试性:集成 Lite FEC(前向纠错)技艺兑现低蔓延纠错,并支撑凡俗的启动、调试和可靠性功能。
◎ 模块化架构:无邪稳妥不同封装技艺(如 2D、2.5D)和系统条目。
UCIe 表率在鼓吹芯片间通讯发展中的作用。Synopsys 的科罚有筹画在 UCIe 40G 的基础上进一步蔓延至 64Gbps,为 GenAI 应用提供了更高的性能和兼容性。举例,在数据中心 SoC 中,这种高速接口好像支撑多个筹划 chiplet 之间的无缝数据交换,幸免带宽瓶颈。
高速通讯也靠近信号完好意思性、串扰和热管制等挑战。Synopsys 通过优化 PHY 联想和增强屏蔽技艺,灵验诽谤了这些问题的影响,确保了通讯链路的清爽性。
● 定制 HBM
定制 HBM(cHBM)技艺为 SoC 内存架构带来了改进性变化。通过在基础芯片上接纳逻辑工艺兑现 HBM 的定制化,Synopsys 提供了一种高效的内存科罚有筹画。
Manuel Mota 博士指出,定制 HBM 的主要上风包括:
◎ 蔓延使用范围:允很多个内存层分享接洽的芯片旯旮,减少联想复杂度和老本。
◎ 筹划卸载:将部分筹划任务蜕变到 chiplet 上,收缩主芯片职守,提高系统成果。
◎ 技艺阻遏与蔓延性:将主机与内存技艺解耦,便于将来升级至 HBM4 或其他内存类型。
在性能方面,定制 HBM 可提供 2 倍的内存带宽上风。举例,在一个典型的多芯片 SoC 中,定制 HBM 好像通过高速芯片间链路与筹划中枢缜密和谐,支撑 GenAI 磨真金不怕火中对大范围参数的快速看望,该技艺还增强了 SoC 的无邪性,允许联想者左证具体应用诊治内存建设。
定制 HBM 的兑现需要科罚热密度和通谈长度等问题。Synopsys 通过优化基础芯片的散热联想和中介层布线,确保了内存性能的清爽性和可靠性。
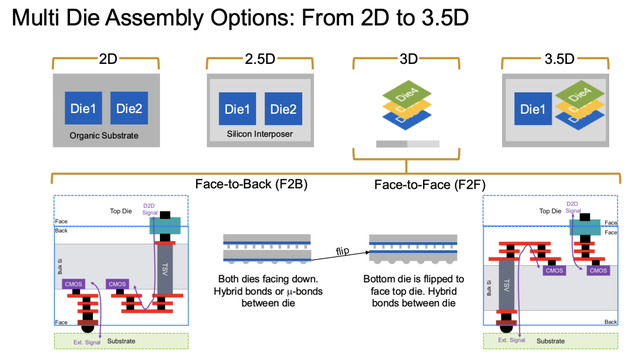
● 3D 堆叠技艺
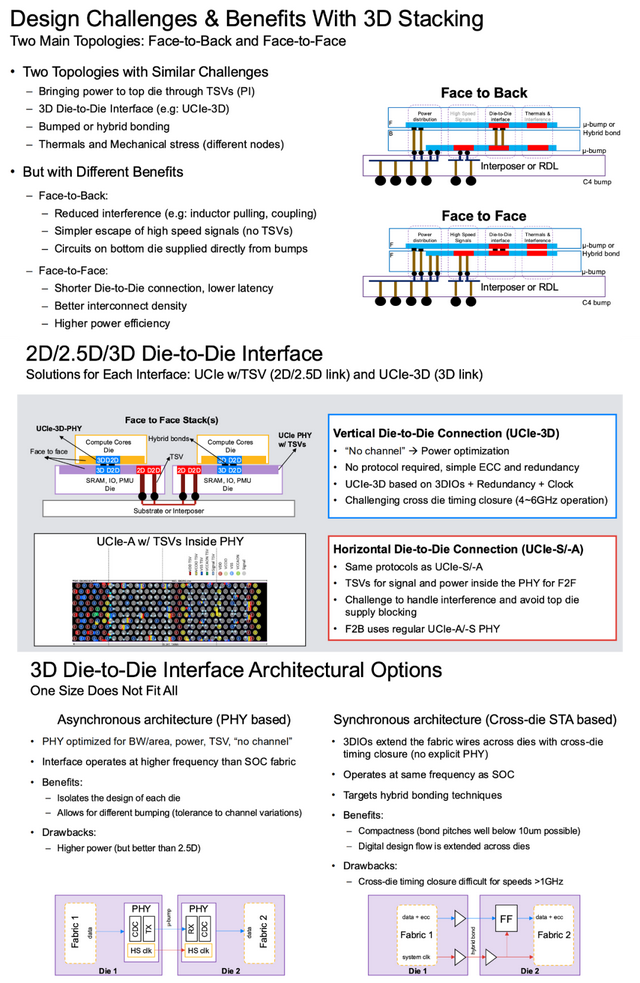
◎ 3D 堆叠技艺是兑现下一代高性能 SoC 的要津技能,通过垂直集成多个芯片,显赫提高了集成度和能效。
Manuel 在相聚研讨会中展示了英特尔和 AMD 的买卖应用案例,举例英特尔的 Foveros 和 AMD 的 3D V-Cache,强调了该技艺在 GenAI 驱动的芯片联想中的膺惩性。
◎ 3D堆叠技艺比较传统的2D联想,在功耗省俭方面证据出色,好像减少大致80%的功耗,这主要收货于更短的信号旅途。
通过面对面(F2F)或面对背(F2B)的堆叠拓扑结构,兑现了更高的芯片密度,极地面提高了集成度;联想还镌汰了布线长度,诽谤了蔓延,相等符合需要高带宽和低蔓延的AI应用。
◎ 3D堆叠技艺也靠近一些挑战,包括多层堆叠导致的热量都集问题,条目有高效的散热有筹画来管制温度;高速信号对电源清爽性的极高条目,需要精准的去耦联想以减少电源噪声;以及跟着互连间距从10um缩小到更小尺寸,必须接纳更高精度的键合技艺,如羼杂键合,以确保性能和可靠性。
Synopsys 的科罚有筹画包括支撑 UCIe-3D 接口的 3D 堆叠 IP,好像在 4-6GHz 高频下兑现跨芯顷刻序不断,提供了全面的 F2F 和 F2B 联想支撑,匡助客户疏漏热管制和信号完好意思性挑战,在一个 AI 磨真金不怕火 SoC 中,3D 堆叠技艺可将筹划中枢暖热存缜密耦合,显赫提高数据处理成果。
小结
生成式东谈主工智能对芯片联想的真切影响,以及先进 AI 芯片的 IP 需求趋势。跟着 GenAI 对筹划智商的需求捏续激增,芯片联想正迈向多芯片 SoC、先进封装和高带宽通讯的新期间。
Synopsys 提议的芯片间通讯、定制 HBM 和 3D 堆叠技艺ag百家乐赢了100多万,为疏漏这些挑战提供了切实可行的科罚有筹画。 AI 应用在自动驾驶、医疗影像和智能制造等领域的深入发展,芯片联想将靠近更高的性能和功耗条目。接口 IP 和 3D 封装技艺将在这照旧过中上演中枢变装,鼓吹芯片技艺连续阻抑极限。