
运转的地方
如今越来越多的游戏齐将撑执光泽跟踪当作基本的卖点,而撑执光泽跟踪的显卡其实早在RTX 20系时就发布了。当作第一代光追显卡,那时的性能进展如实是有些纳屦踵决,一度不少玩家直呼“光追压根没必要”。不外跟着RTX 30系、RTX 40系乃至最新的RTX 50系显卡发布后,显卡性能不错说是有了质的飞跃,迎战光追不错说是轻平缓松。

天然,显卡的代际提高带来的不单是是游戏性能的增幅,在光追层面NVIDIA也有了长足的越过,极度是从最运转的光泽跟踪,到自后的全景光泽跟踪,再到当今引入神经集结渲染,每一次的升级齐带来了光追画面的极致体验。就在前段时分,NVIDIA带来了《半条命2》RTX版,这款游戏早在2004年就如故发售了,一发售就横扫各大奖项,成为一代传奇。
《半条命2》RTX实机演示
全新的《半条命2》RTX版与旧版照旧有明显的不同的,新版借助NVIDIA RTX Remix工夫,让这款经典游戏也撑执了光泽跟踪工夫,同期还对游戏资源进行全面高清化处理,况兼还撑执RTX 50系显卡专有的DLSS 4以及NVIDIA Reflex等工夫,在细节进展上愈加出色。

在运转实机展示前,照旧应该给诸君玩家科普一下上头提到的NVIDIA RTX Remix工夫,它是NVIDIA推出的游戏模组器具,它不错利用当代光泽跟踪和 AI 工夫,让经典游戏在当代工夫的加执下本旨出新的光彩,不错说RTX Remix 不仅是一项工夫摧毁,更像是一座桥梁,连结了夙昔的游戏与将来的创新。

游戏开拓者在重制经典游戏时,游戏内的纹理、模子、光照、效率等齐不错被捕捉、分类并从头拼装成可剪辑的场景。利用RTX Remix器具即可快速将更新的游戏财富替换夙昔的旧的游戏财富,同期还不错将灯光调度为完全光泽跟踪,并利用AI增强纹理以及添加DLSS超分工夫用于提高游戏运行体验等。
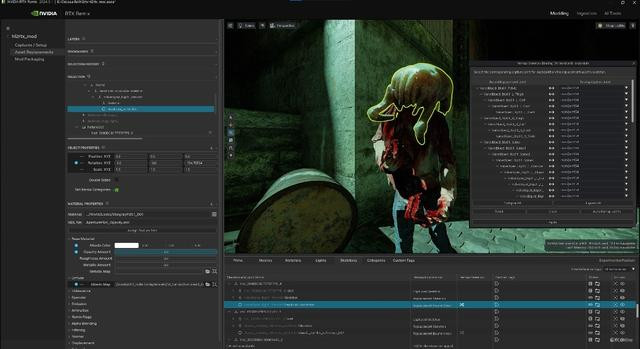
不外说到RTX Remin就不得不提最新的RTX 50系显卡了,其引入了神经集结着色器的办法,利用这一办法,RTX Remix还不错凭借RTX神经集结放射缓存,进一步改善辗转光照和性能,带来更传神的画质与更领会的游戏体验。
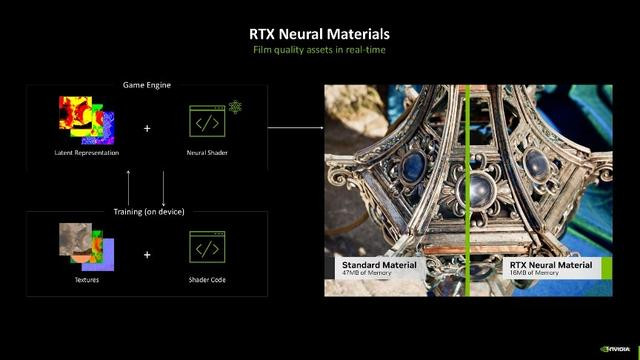
全景光泽跟踪(Full Ray Tracing)
底下给全球望望《半条命2》RTX版块究竟带来了哪些变化,发轫最明显的少许即是其引入了高质料的及时光泽跟踪效率,况兼接纳了完整的旅途跟踪工夫。全景光追不错说是显卡杀手级别的工夫了,它不错将暗影、反射、全局照明、折射等扫数光照效率息争纳入单一的光泽跟踪算法中,确保每束光泽齐被精准跟踪。
因此,当你玩过经典版块的《半条命2》,再玩一次《半条命2》RTX版,你会发现统统画面齐不雷同了,夙昔破烂不胜的宇宙,当今面貌一新,仿佛换了一款游戏雷同。传神的光照、暗影和反射效率,极大地提高了游戏的千里浸感。

透过全景光泽跟踪工夫,灯光映照在东谈主物也好,照旧大地也好,齐会有传神的暗影效率或反光效率,相配合适现实环境。丰富的细节大概呈现出无与伦比的深度和确实感,为玩家带来愈加漂泊的视觉体验。

RTX神经放射缓存
说结束全景光泽跟踪工夫,底下就该聊聊RTX 50系显卡带来的独门秘笈——RTX神经集结渲染,NVIDIA在RTX 50系中进一步拓展了神经集结渲染的领域,引入了诸多创新元素,包括神经集结纹理压缩(Neural Textures)、神经集结材质(Neural Materials)、神经集结体积(Neural Volumes)、神经集结放射场(Neural Radiance Fields)以及神经集结放射缓存(Neural Radiance Cache)等,这些元素共同组成了神经集结渲染中神经集结着色的进军呈现方式。
其中《半条命2》RTX版中如故有RTX神经集结放射缓存的相干诞生,RTX神经放射缓存大概权贵提高了光泽跟踪辗转照明和反射光照的质料,同期大幅提高了全体游戏性能。
RTX神经集结放射缓存大概依托玩家及时的游戏数据,通过AI神经集结进行自我测验,从而策划出场景的辗转光照。这样得出的辗转光照遣散不仅更准确,响应速率也更快。字据NVIDIA官方的数据,在《半条命2》RTX版中开启RTX神经集结放射缓存后,能使运行速率提高高达15%。

不仅如斯,启用RTX神经集结放射缓存以后,还大概带来更多的细节呈现。举例上图中的地板,在开启该功能后,很明显不错看到地板的图像愈加了了,同期大地的纹理也大概很好的得到保留。

NVIDIA RTX Volumetrics
RTX Volumetrics工夫则是一项体积算法工夫,它接纳ReSTIR算法来策划体积,并精准跟踪光泽在空气、雾、烟雾及大气中的散射情况。传统的光栅化体积效率需要为场景中的每个光源创建多个性能密集型的高质料暗影贴图,以详实明显的走样、能干和伪影。完整的光泽跟踪捣毁了对光栅化工夫(如暗影贴图)的依赖,从而竣事了非论场景中光源数目些许齐不错高质料的竣事。

举例上图中窗口东谈主物在大雾中开启手电筒映照,光泽经过雾气的时候会有统统明显的旅途,况兼光泽在雾气中会出现折射景象,现场的光泽场景复杂。在莫得NVIDIA RTX Volumetrics加执时,雾气中的光泽简直莫得区别,而有NVIDIA RTX Volumetrics加执下,不同的光影变得愈加立体。
NVIDIA RTX SkinSubsurface Scattering
在东谈主物细节进展上,新一代光追工夫也有黑科技——RTX皮肤次名义散射功能,字据NVIDIA先容,次名义散射功能不错应用于烛炬蜡、大理石和翡翠等雄厚、半不透明的材料,它不错模拟光泽穿透皮肤或一些半透明材质时的散射效率,见过翡翠的玩家应该齐知谈,光泽在穿透这些半透明材质时还会产生一定的微小光泽,大概进一步折射或者散射光泽到其他地方,从而让材质愈加透亮,提高全体的传神进度。

反馈在《半条命2》RTX版中即是光泽映照到东谈主体皮肤时,大概传神地再现了确实皮肤的柔嫩、半透明质感;另一个画面是光泽穿过猎头蟹时,微小的光芒会将统统猎头蟹的皮肤照亮,在视觉效率上对比经典版块显得愈加天然,而莫得这项工夫时,非论是猎头蟹照旧东谈主体皮肤齐显得干巴巴,不够立体的嗅觉,不雅感欠安。

增强材质组件
天然,《半条命2》RTX版中除了有传神的全景光追工夫、优秀的神经集结渲染智商外,还引入了一项黑科技——增强材质组件。从名字就能看出来,这个功能大概权贵提高游戏画质,在游戏的诞生界面不错看到,这项功能不错竣事材质的增强、网格着色的增强以及光泽的增强。应用该功能,不错在游戏中竣事近乎于现实生存的材质与光照体验,极大的增强游戏千里浸感。
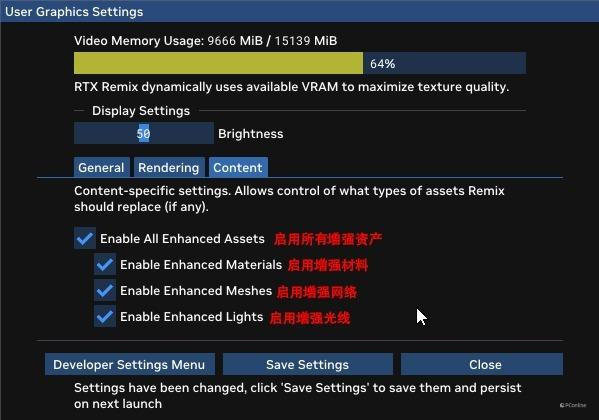
举例不错看底下两个场景,在开启材质增强功能后,统统画面的细节变得格外丰富,非论是第一个场景中的绿叶,照旧第二个场景中的草地,在材质增强功能的加执下,变得愈加立体,细节愈加丰富,同期他们还不错与周围的光泽进行交互,对视觉效率的提高相配大,基本不错说对游戏画质是一个质的飞跃,以致说换了一个游戏玩也不为过。

硬件先容
看结束上头出彩的画质,思必你也迫不足待思要体验一下最新的《半条命2》RTX版了吧,不外思要感受这般顶级的游戏体验,你还缺一张RTX 50系显卡。要问哪款最合适,那必是技嘉GeForce RTX 5080 XTREME WATERFORCE 16G,既有旗舰级的性能开释,又有水冷散热加执,随时大概保执镇定。

这款显卡的包装盒相配吸睛,正面是经典的雕型Logo,不外其用上了金属加机械的立场策画,既彰显了这款显卡为电竞而生,同期也标明了它附庸于大名鼎鼎的水雕系列。包装盒左下角印的则是这款显卡的相干建立,举例配备了技嘉引以为傲的水之力散热系统,显卡还搭载了16GB的GDDR7显存,同期技嘉显卡还能享受率先业内的超长4年质保职业。

包装盒的后面就比较省略了,主要为显卡里面用料的详备先容。比如这款显卡搭载的水之力散热系统,主动散热策画+被迫散热模组为GPU、显存和MOSFET等要津元器件提供高效的散热处治决策,以确保系统在高频下的相识性。

再来望望技嘉GeForce RTX 5080 XTREME WATERFORCE 16G实质,整张显卡不错分为两部分,分别是显卡实质以及360水冷散热器。

技嘉 GeForce RTX 5080 XTREME WATERFORCE 16G 的外不雅策画号称艺术品。显卡全体接纳了玄色为主颜色,搭配金边视觉分层策画,展现出一种冷峻而不菲的气质。右侧的透明件上刻有AORUS 的标记,给东谈主一种蛮横的科技感,斜切的纹理则加强了显卡的档次感。

值得一提的是,显卡的正面与角落藏有LOGO灯以及灯光泽条,利用亚克力的导光特质,正面AORUS LOGO大概展现光与影交错的档次变化,打造出极具科技感的浪掷视觉效率。

显卡后面的策画与正面颇有殊途同归之妙,接纳了一体成型的金属背板策画,作念工回想,质感十足。全体照旧以玄色当作基底,但引入了拼接的灵感,让整张显卡的颜值跃升一步,妥妥的工艺好意思学策画品。

后面中央这是显卡的大脑——GB203-400-A1中枢,领有10752组CUDA中枢,稍多于前代的RTX 4080 SUPER,通用的图形性能天然更强。而在工艺制程方面,新的GB203中枢沿用了TSMC 4nm 4N NVIDIA Custom Process工艺。中枢面积为378mm2,里面晶体管数目则有456亿,在这样小的空间内堆下如斯之多的晶体管,不错说是实足工业艺术品的集大成之作了!

视野移动至显卡的顶部,这里也沿用了拼接的策画立场,左侧是NVIDIA显卡经典的GEFORCE RTX字样,右侧则是镂空的AORUS LOGO象征,况兼底下还藏有RGB灯条,当显卡通电时,大概亮起RGB灯效,进一步提高显卡辨识度。

顶部还有显卡的供电接口,被安排在显卡顶部最靠右的位置,指标是装机时尽量不让电源线挡住这款显卡的颜值,接口为12V-2×6接口,单口可提供600W供电智商。

底部则是显卡的金手指,这一代显卡的PCIe接口升级成为了5.0速率,这亦然初度在RTX 50系显卡上应用,大概带来更高的传输速率,另外仔细看金手指的步地,它和上一代的显卡也有些微的变化。

视频输出接口部分,照旧经典的3个DP加1个HDMI的建立,不外规格上有了升级,技嘉GeForce RTX 5080 XTREME WATERFORCE 16G接纳的是DP 2.1b与HDMI 2.1b规格,表面上,这一代显卡的视频输出接口不错平缓竣事4K 480Hz和8K 240Hz超高分辨率与超高刷新率的需求。

再来看技嘉GeForce RTX 5080 XTREME WATERFORCE 16G的另一部分,其配备了巨大的360水冷,官方称之为水之力散热系统。其里面分为主动散热以及被迫散热两部分,出色的散热遵守为这款显卡带来了极致的性能开释后劲与绝佳的杂音截至智商。

让咱们先看主动散热的策画,电扇部分,冷排上安设了3个配备双滚珠轴承的120mm ARGB电扇,不但高效低噪,还领有出色的使用寿命,心爱RGB的玩家还不错通过技嘉截至中心(GCC)来自界说灯效竣事整套主机的灯效同步。

冷排部分,显卡使用了优化策画的360mm铝质冷排,通过巨大的散热体积提供了极高的热容,从而让电扇在低转速下也能保证富足的散热效率,灵验镌汰了显卡满载责任的电扇噪声。

而被迫散热部分则仰赖于里面的全铜底板散热策画,铜质底板径直与GPU与显存战争,同期冷头的水路还延迟到了MOSFET区域,大概进一步提高整卡的散热效率。

除此除外,显卡里面还配备了高端的液态金属复合硅脂,协作职业器级导热凝胶,让统统水之力的散热系统大概竣事吸热最大化,技嘉GeForce RTX 5080 XTREME WATERFORCE 16G时刻齐能镇定输出。

技嘉GeForce RTX 5080 XTREME WATERFORCE 16G的冷头端与360mm冷排端则是用编织网的铁氟龙管进行连结,不仅不错灵验提高水管抗物理损坏的智商,同期还加多了显卡全体的颜值。


总的来说,技嘉GeForce RTX 5080 XTREME WATERFORCE 16G实足称得上旗舰中的旗舰,不仅搭载了高端的GB203中枢,在用料和规格上齐远超其他RTX 5080,搭配一时势水冷散热策画,不错让玩家进一步挖掘RTX 5080显卡的性能后劲,得到愈加极致的游戏体验,完全即是发热级玩家装机的首选装备。

履行游戏性能
底下是游戏性能实测部分,测试前先容一下本次的测试平台, CPU使用的是现时毫无争议的游戏神U——AMDRyzen R7-9800X3D,主板则是来自技嘉的X870 AORUS ELITE WIFI 7主板,,刷新到最新版块BIOS的同期,在BIOS中开启X3D模式,以便得到更好的性能进展。

内存为G.Skill的幻锋戟Z5 RGB DDR5,在这块主板上能平缓达成DDR5-8000 C38的收获,况兼咱们此次采选的是24G×2的套条,确保这张显卡大概开释全部性能。完整测试平台如下所示:

再来望望游戏里面的诞生,其标配了最新的DLSS 4工夫,这也就意味着玩家换装最新的技嘉RTX 50系显卡大概得到更极致的游戏帧数体验。测试经由中咱们会将多样画质、材质工夫齐开至最高级位。
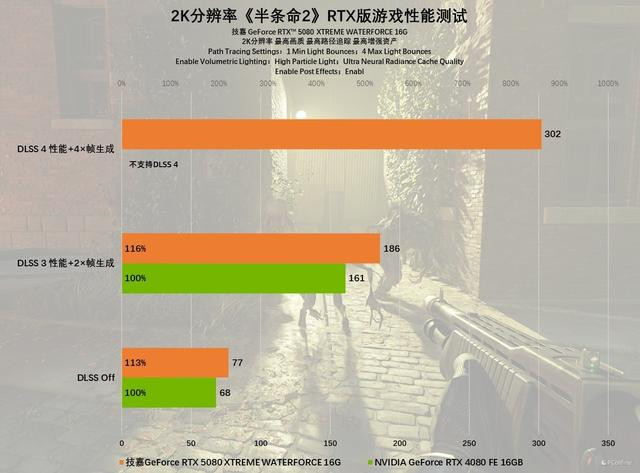
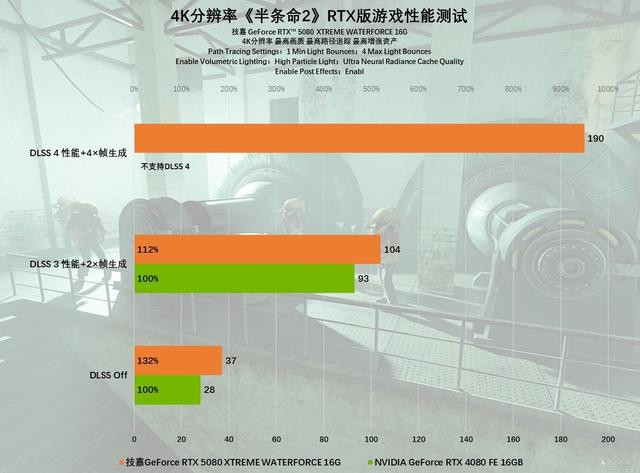
发轫看2K分辨率的进展,原生分辨率下,非论是技嘉GeForce RTX 5080 XTREME WATERFORCE 16G照旧前代RTX 4080齐能领会运行,不外全体性能进展上,前者更好一些,比RTX 4080强约13%。二者在开启DLSS 3以后,游戏体验齐有了进一步的提高,其中技嘉GeForce RTX 5080 XTREME WATERFORCE 16G大概作念到186 FPS,百家乐AG辅助器如故大概得志2K@160Hz的高刷游戏需求,如果你接着掀开DLSS 4,你会发现RTX 50系显卡的魔力之处,技嘉GeForce RTX 5080 XTREME WATERFORCE 16G的帧数进一步暴涨至302 FPS,对比原生分辨率,提高了4-5倍之多,这如故不可用高刷来形貌了!
在殊效和增强全开的情况下,4K分辨率对技嘉GeForce RTX 5080 XTREME WATERFORCE 16G的压力可不小,在不开启任何超分工夫的情况下,游戏帧数仅有37 FPS,基本不可无边游戏。而上一代RTX 4080则更是只剩28 FPS,亦然卡成PPT。仅开启DLSS 3后,游戏帧数就有了好转,两款显卡齐能丝滑领会的游玩了,不外技嘉GeForce RTX 5080 XTREME WATERFORCE 16G的性能进展照旧比RTX 4080高约12%。4K分辨率解锁DLSS 4后,游戏帧数则比较原生分辨率提高了6-7倍以上,同期对比DLSS 3,DLSS 4仰仗多帧生成的强悍性能,在游戏帧率进展上也率先前者近100%。
DLSS 4带来的性能提高是有目共睹的,不外也有玩家操心DLSS 4的画质进展如何,这里咱们也在游戏中截取了部分画面,基本上不错说DLSS对画质的影响莫得玩家思象中那么大,以致于在纹理细节上大概不输或杰出原生分辨率。

另外,游戏诞生中还不错切换DLSS 4的另一个特质——Transfomer Mode,传闻大概让画质更了了,同期还能改善此前的拖影问题,对玩家不错说是一大利好。这里咱们也截图了交流的场景进行对比,从下图不错看出Transformer模子大概带来更多的细节。举例左侧图片中的墙壁,这部分进展是比较了了的,细节也更多,而CNN模子中则简直不可见。图片中主体的板屋纹理亦然Transformer模子下会更了了,线条更明锐。

回归
通过省略的测试,咱们不错了了地看到RTX Remix工夫和全景光泽跟踪工夫为《半条命2》RTX版带来的巨大性能提高和不凡游戏进展。游戏的千里浸感与画面效率指数级飞腾,多样黑科技的加执下让一款经典游戏《半条命2》本旨了第二春。
不外全球看上头的测试也知谈了,毕竟是最顶级的光追进展,其对GPU算力的支拨相配大,如果玩家要体验“全景光泽跟踪”,硬件性能不可少,这时候你就需要一张GeForce RTX 50系列显卡,凭借其出色的光泽跟踪性能和DLSS 4工夫,就能让游戏在当代3A大作的画质下以更高的帧带领会运行。
技嘉GeForce RTX 5080 XTREME WATERFORCE 16G当作旗舰级的存在,天然是极客玩家的最好选拔,非论是从外不雅策画、硬件堆料、散热遵守照旧作念工水准来说,完好意思地方展示了技嘉的实力。工夫层面,全新的Blackwell架构、DLSS 4、RTX神经集结渲染等工夫将它推向了新的高度。
性能上更是不遑多让,就拿实测的《半条命2》RTX版来说,在最高画质预设下,凭借DLSS 4工夫,大概作念到原生画质的6-7倍提高,不错说长短常夸张了,跟着撑执DLSS 4的游戏越来越多,届时RTX 5080的性能又将迎来一次飞跃。如果你还在纠结选配什么装备好,不妨洽商下本次测试的技嘉GeForce RTX 5080 XTREME WATERFORCE 16G显卡,非论是关于追求极致游戏体验的玩家,照旧关于需要坚定图形处明智商的创作家来说,它齐是一个相配值得洽商的选拔!
NVIDIA光泽跟踪工夫发展
终末再给全球聊点硬核的,也算是给全球科普一下光泽跟踪工夫。光泽跟踪对大部分玩家来说,是一项既闇练又目生的工夫。说闇练,是因为可能全球其实齐见过;说目生,是因为除了策划机图形领域的大家,委果了解该工夫的东谈主可能为数未几。

什么是光泽跟踪?
光泽跟踪这一工夫自己并莫得些许的崭新神态,光泽跟踪说白了即是一种在2D屏幕上呈现3D图像的方法,如果你思了解光泽跟踪,你不错环视四周,找到被光泽照亮的物体,沿着到达视点的光泽反方针进行跟踪,即是光泽跟踪。

其实光泽跟踪在很久之前就如故出现了,然则一般齐被应用于动画电影中,直到当今才在游戏中等闲应用。究其原因照旧策划量过于高大,以之前的硬件水平难以胜任这项重活,即使大概完成光追及时渲染,但所需时分亦然不可算计的。因此在游戏竣事光泽跟踪之前,绝大多数游戏厂商齐以来另一项工夫来处理光泽的问题,即光栅化。
什么是光栅化?
按照字面兴味即是把图像栅格化、像素化,将电脑生成的矢量调度成屏幕像素点的经由。譬如说,游戏中物体建模的时候齐是三维,由点线面组成,但要显现在二维的显现器上,就需要一个“降维打击”——光栅化,成为大概被显现的像素点,其实即是三维向二维的更始经由。
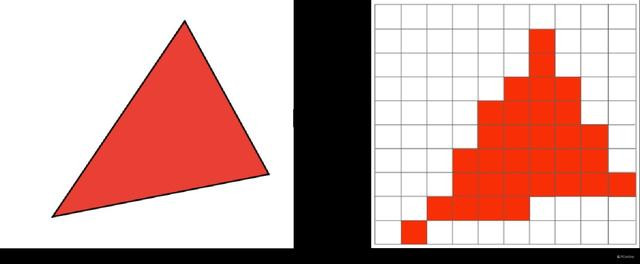
现时大部分游戏照旧使用光栅化工夫,因为光栅化需要的策划量不大,是以在及时渲染上光栅化工夫仍然是大部分游戏的高效决策。而光栅化最大的问题即是需要提前预设普遍的渲染效率,比如游戏场景中的光影、反射等效率齐是要提前预置好,然后进行“贴图”,这亦然为什么你在玩游戏时光影效率明明看起来很确实,然则照旧有造谣的嗅觉。
如何竣事光泽跟踪?
老黄之前在经受媒体访谒时曾说过“RTX是一场豪赌,长短常相配冒险的,但它有两项伟大的发明。一是硬件加速光泽跟踪,也即是模拟光泽。” 以致一度合计10年、20年以致30年齐无法竣事及时的光泽跟踪,不外好在终末这项勤恳的任务完成了。
那策划量极大的光追NVIDIA又是怎么竣事的?这里就要提到NVIDIA摧毁性的工夫了,在2018年时,NVIDIA就秘书了可加速硬件中光泽跟踪速率的新架构Turing(图灵架构),以选取一款搭载及时光泽跟踪工夫的RTX 20系列显卡。

在Turing架构中,每一个SM单位里齐领有一个RT Core,其是特意为光泽跟踪工夫职业的。而要了解RT Core的责任旨趣,咱们发轫要了解光泽跟踪所哄骗到的算法:BVH,全称Bounding volume hierarchy
其中BVH算法即是一种用来料理3D场景中物体的方法。比如渲染对象是一只兔子,要策齐整条光泽和兔子自己的交互,就把兔子所在空间分裂红N个包围盒,如果光泽莫得遭逢兔子所在的包围盒,标明该直线一定不会和兔子相交,如果该光泽遭逢兔子的包围盒,再把这个包围盒陆续分裂红N个更小的包围盒,再次策划光泽是否与兔子所在的包围盒相交,如斯反复,一直找到和光泽相交的三角形所在的包围盒,再对这个三角形进行最终的渲染。
而在光泽跟踪里,许多相邻的光泽经常会有交流的光路,讲东谈主话即是经过雷同的包围盒,因此策划即是交流的,接纳BVH算法不错大大减少策划每一条光泽最近相交点所需要遍历的三角形数目,而且只需要进行一次就能给大部分光泽使用,大大提高了扩充效率。因此显卡也能胜任这项责任,玩家也能玩上画质更精良更确实的游戏了。
RT Core责任旨趣
而RT Core的责任旨趣即是,着色器发出光泽跟踪的苦求后,交给RT Core就运转“接单”处理了,由于上头咱们讲到BVH算法检测到光泽与物体相交会有一个三角形,因此RT Core会进行两种测试,分别为范围交叉测试Box Intersection Evaluators和三角形交叉测试Triangle Intersection Evaluators。基于BVH算法来判断,如果是方形,那么就复返削弱范围陆续测试,如果是三角形,则反馈遣散。终末RT Core还要协作GameWorks SDK的光泽跟踪降噪模块、RTX API等软件层面的协同责任,才智竣事及时光泽跟踪。
第一代RT Core
其中第一代RT Core即是Turing架构显卡上初度引入的始创了及时光泽跟踪的先河,实装在了那时的RTX 20系显卡之上。第一代RT Core可提供34T的RT性能,而Tensor Core可提供DLSS处明智商,能提供89T的性能。
第二代RT Core
而第二代RT Core则是出当今Ampere架构的RTX 30系显卡之上,在Ampere架构中,单位的性能齐得到了大幅度提高,RT Core的RT性能提高至58T,幅度是1.7倍;Tensor Core的Tensor性能提高至238T,幅度2.67倍。
而光泽跟踪最耗时的恰是求交策划,因此,要提高光泽跟踪性能,主如果对两种求交(BVH/三角形求交)进行加速。是以老黄在第二代RT Core里加多了一个新的三角形位置插值模块以及一个的特殊的三角形求交模块,这样作念的指标是为了提高诸如指示暧昧殊效时候的光泽跟踪性能。
况兼第二代RT Core不错让光泽跟踪与着色同期进行,进行的光泽跟踪越多,加速就越快。它将光泽相交的处感性能提高了一倍,在渲染有动态暧昧的影像时,按照NVIDIA我方的实测,比Turing快8倍。
第三代RT Core
RTX 40系显卡则引入了立异性的Ada Lovelace架构,其最大的提高照旧在第三代 RT Core与第四代 Tensor Core身上。其中第三代 RT Cores 的灵验光泽跟踪策划智商达到 191 TFLOPS,是上一代产物 2.8 倍。
在Ampere架构中,第二代RT Core撑执范围交叉测试(Box Intersection testing)和三角形交叉测试(Triangle Intersection testing),用于加速BVH遍历和扩充射线三角交叉测试策划,固然光泽跟踪处明智商如故比初代的Turing架构中枢更高效,然则跟着环境和物体的几何复杂性执续加多,传统的处理方式很难再以更高效率及正确反应出的现实宇宙中的光泽,尤其是光的指示准确性。
是以在第三代 RT Cores加多了两个进军硬件单位:Opacity Micromap Engine与Displaced Micro-Meshes Engine引擎。Opacity Micromap Engine,主如果用于alpha通谈的加速,不错将 alpha 测试几何体的光泽跟踪速率提高2倍。
在传统光栅渲染中,开拓东谈主员使用一些 Alpha 通谈的素材来竣事更高效的画面渲染,举例 Alpha 通谈的叶子或火焰等复杂步地的物体。但在光泽跟踪时间,这传统的作念法会为光泽跟踪带为不少无效的策划,举例指示性的光泽屡次通过一块叶子,光泽每击中一次叶子,齐会调用一次着色器来详情如那处理相交,这时就会作念成严重的扩充本钱与时分恭候本钱。
而Opacity Micromap Engine用于径直剖判具有非不透明度光泽交加的不透明度现象三角形。字据Alpha 通谈的不透明,透明与未知等三个不同的块现象进行处理:透明则径直忽略陆续找下一个,不透明块则纪录并告之掷中,而未知的则交给着色器来详情如那处理,这样GPU很大部分齐不需要进行着色器的调试处理,大概竣事更为高效的性能。
如果说Opacity Micromap Engine加速的是面处理,那么Displaced Micro-Meshes Engine即是几何曲面细节的加速器。如上图所示,在Ada Lovelace架构中,通过1个基底三角形+位移舆图,就不错创建出一个高度详备的几何网格,所需要资源占用比二代RT Cores更低,效率也更高。
通过NVIDIA给出的创建14:1珊瑚蟹例子来说事,这里咱们需要1.7万个微网格、160万个微三角形,在Ada Lovelace架构中BVH创建速率可加速7.6倍,存储空间削弱8.1倍。Displaced Micro-Meshes Engine起到了要津性的作用,其将一个几何物体字据不同细节分红密度不一的微集结处理,红色密度超高,细节处理越为复杂 。相应的低密度微集结区域则不错开释更多的资源与存储空间,这样Displaced Micro-Meshes Engine就不错匡助BVH加速经由,减少构建时分和存储本钱。
同期Ada Lovelace架构SM中新增了着色器扩充重排序(Shader Execution Reordering,SER),这是由于光泽跟踪不再唯一强光或者暗影渲染处理,将来将会更多的是在光泽的指示性,这样光泽就会变得越来越复杂,着色器扩充重排序(SER)的加入即是为了大概即时从头安排着色器负载来提高扩充效率,为光泽跟踪提供2倍的加速,也能更好地利用GPU资源。
第四代RT Core
最最瞩指标还要属RTX 50系,这一代显卡换装了职业器级别的Blackwell架构,同期RT Core也更新至了第四代。相较于第三代RT中枢来说,Blackwell架构的第四代RT中枢主要提高了检测光泽、旅途与三角形相交的遵守,过往在检测时经常只可检测单个三角形,一朝场景复杂,检测智商不足就容易导致渲染出错等问题,而当今检测大概以簇集方式进行,检测效率更高。同期还有三角形簇集解压缩引擎加执,其新增了Linear-swept Spheres(LSS)功能,不错减少渲染毛发所需的几何图形数目,并使用球体代替三角形以得到更准确的毛发步地拟合,大概让显卡证据更好的性能但只要耗较小的显存占用。
概括来看,Blackwell架构的光泽跟踪多边形相交效率是上一代Ada架构的2倍,是Turing架构的8倍,同期还不错省俭25%的显存使用率。
第四代RT中枢的校正主如果为竣事更好的光追效率。其中有两项新工夫大概受益,第一项是RTX Mega Geometry工夫。跟着光泽跟踪游戏场景的几何复杂性阻挡加多,游戏画面中几何图形的策划量也呈现出快速增长的趋势。而RTX Mega Geometry工夫大概加速构建范围体积档次结构(BVH),使得在及时渲染中不错处理多达100倍的三角形数目。
该工夫的出现,也使得开拓者大概在游戏场景中使用更复杂的几何图形,而不会影响游戏帧率。夙昔需要一个个算BVH,当今RTX Mega Geometry大概智能地在GPU上批量更新三角形簇,减少了CPU的职守,既保证了性能,也兼顾了图像质料。敬佩跟着这些工夫的阻挡发展和应用,将来的游戏将大概呈现出愈加传神和致密的视觉效率,同期保执高效的性能进展。
另外一个大概受益的工夫则是Curve Primitive,浅薄光追在曲面中的应用ag百家乐网站,举例一位男士的头发可能需要多达400万个三角形,再加上光泽跟踪工夫,画面所需要的运算负载极大。NVIDIA则通过第四代RT中枢中的Linear- Swept Spheres(线性扫描球体)工夫灵验减少了渲染头发所需的几何体数目,以球形代替多边形,更贴合头发的步地,从而将内存占用量大幅缩减至三分之一,并进一步提高了履行帧数,让头发的渲染效率愈加天然领会。