发布日期:2024-12-16 01:06 点击次数:56
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
7B参数的Qwen2.5数学推理施展高出o1-preview,这是如何作念到的?!
靠的便是MSRA最新的鼎新算法,rStar-Math。
通过代码增强CoT、蒙特卡洛树搜索(MCTS)等,rStar-Math能让小·大模子在不依赖蒸馏教师模子的情况下,通过多轮自我进化的深度念念维,掌执数学推理。

况兼军功赫赫:
在好意思国数学竞赛AIME 2024测试中,rStar-Math平均惩办了53.3%的费事(OpenAI o1-preview为44.6%),击败总共其它开源大模子,一举成为最智慧的高中生数学top20%。
在MATH基准测试中,rStar-Math将阿里开源大模子Qwen2.5-Math-7B的准确率,从58.8%拉升到90.0%;Qwen2.5-Math-1.5B的准确率从51.2%拉升到87.8%;Phi3-mini-3.8B的准确率从41.4%提高到86.4%
——这些得益一起一起高出了OpenAI o1-preview。
就说牛不牛吧!

小声说,微软最近有一股在小·大模子圈子里重拳出击的态势:昨天刚开源了现时最强的小·大模子,14B的phi-4;今天又推出了rStar-Math,论文中直指其面向小言语模子(SLM)。
这个趋势刚有点苗头,坐窝引得全网酌量连连。
有网友不禁开首估量:
咱便是说,有莫得一种可能,在固定盘算预算的情况下,小·大模子其真的某些推理问题上,它便是抢过大模子呢?
rStar - Math如何作念到的?
Let’s 发问:
让小言语模子能和o1的数学推贤慧商相失色甚而超越,且无需从高档教师模子中蒸馏,它如何作念到的?
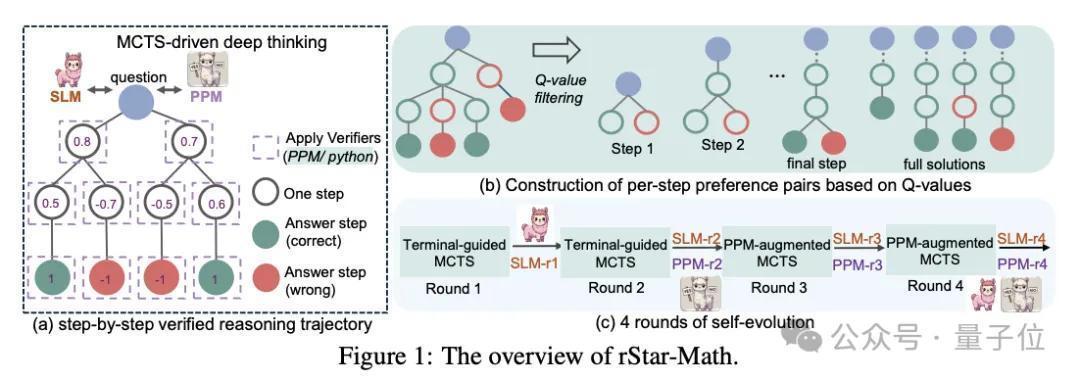
MSRA在论文中暗示,这是通过蒙特卡洛树搜索(MCTS)进行深度念念考来完了的,况兼,其中一个数学策略小模子在基于小模子的历程奖励模子的指导下实行测试时搜索。
现时,业界精深依赖天然言语生成的推理门径来普及数学推理模子的智商。
这种行动很直给,但其要道在于教师一个庞杂的策略模子来生成惩办决议门径,还需要教师一个可靠的奖励模子来进行准确评估。
但是上述两个模子齐依赖于高质地的教师数据。
人所共知的坏音书是,高质地的数学推理数据在当今瑕瑜常相等稀缺的,同期高质地的合成数据也存在一定bug。
而且实践历程标明,它容易变成很多不联系、无须要的门径,或产生差错。
当这种豪侈和失实出当今复杂的数常识题中时,一般很难被察觉。
现存的宗旨,比如基于蒸馏的数据合成行动来教师策略模子(如扩大GPT-4蒸馏的CoT数据),还是彰着的出现请教递减,且最终展现的智商无法高出其他教师模子。
与此同期,扫尾今天,教师可靠的PRM(Process Reward Model,历程奖励模子)进行数学推理仍然是一个悬而未决的问题。

MSRA这次推出的rStar-Math,就引入了三项鼎新行动,来应答教师两个小模子的挑战:
代码增强CoT数据合成步阅历程奖励模子教师行动四轮自我念念维深度进化咱张开来说说~
代码增强CoT数据合成行动rStar-Math遴荐使用代码增强CoT来惩办上述费事。
该行动实行平庸的MCTS部署,从而生成具有自我注目的MCTS Q值的逐渐考据推理轨迹。
具体来说,一个数常识题的求解,会在MCTS内被意见为多步生成。
模子在生成每一步推理时,当作策略模子的哪个SLM会对候选节点进行采样,不仅生成这一步的CoT念念维脸解说,还生成相对应的Python代码。
为了考据生成质地,唯有告捷实行Python代码的节点才会被保留,从而减少中间门径的差错,确保每一步推理的正确性。

在此基础上,为了进一步确保推理门径的质地,rStar-Math使用了MCTS来生成逐渐推理轨迹(用来意见复杂的数常识题为多个单步生成任务)。
多半的MCTS回滚会左证每个中间门径对最终正确谜底的孝敬,自动为其分派一个Q值。
有助于产生更多导致正确谜底的轨迹的门径将被赋予更高的Q值,并被以为具有更高的质地。
这确保了SLM生成的推理轨迹,是由正确、高质地的中间门径构成的。
历程奖励模子教师行动现阶段,多数大模子在惩办推理数常识题时,齐靠近一个问题:
无法无法提供细粒度的门径级反应,以匡助其在推理历程中作念出更优的遴荐。
尽管使用了平庸的MCTS部署,仍会出现Q值不够精确的情况,这就导致无法对每个推理门径进行评分。

为此,rStar-Math通过引入用于教师充任历程偏好模子(PPM,Process Preference Model)的SLM,来可靠地为每个数学推理门径展望奖励标签。
PPM的中枢念念想,是通过构建门径级的正负偏好对来教师模子,而不是径直依赖于精确的门径级评分。
它左证Q值为每个门径构建偏好对,并使用成对名次耗损来优化PPM对每个推理门径的分数展望,完了可靠的瑰丽。
如上所述,Q值天然不精确、含噪声,但PPM不错愚弄它,可靠地分裂正(正确)门径和负(不联系 / 差错)门径。
四轮自我念念维深度进化由于SLM智商较大模子更弱,团队联想了四轮自我念念维深度进化,以逐渐生成更高质地的数据,并通过更具挑战性的数常识题扩张教师集。
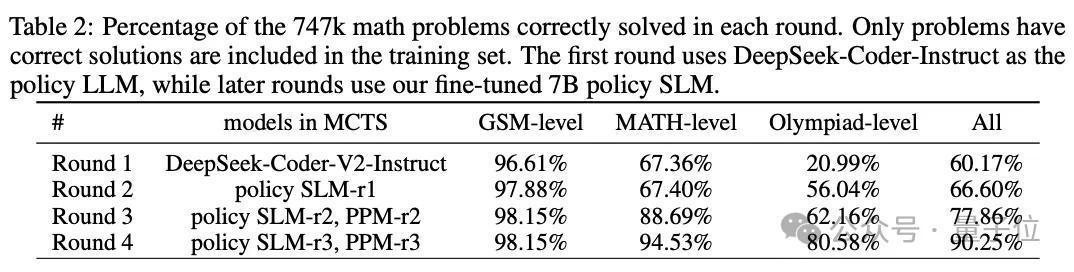
值得看重的是,团队滥觞遴荐了一个包含747k个数常识题的开源数据集。
但在每一轮中,谈论团队莫得使用747k数学数据鸠合的原始惩办决议,而是进行了平庸的MCTS部署——
四轮中的每一轮,齐使用MCTS生成逐渐考据的推理轨迹,然后将其用于教师新策略SLM和PPM;然后又鄙人一轮中应用新模子,以生成更高质地的教师数据。
四轮自我念念维深度进化具体如下。
第一轮:
通过监督微调对基础模子进行初步转变,AG百家乐计划为后续的自我进化奠定基础。
转变后的模子暗示为SLM-r1。
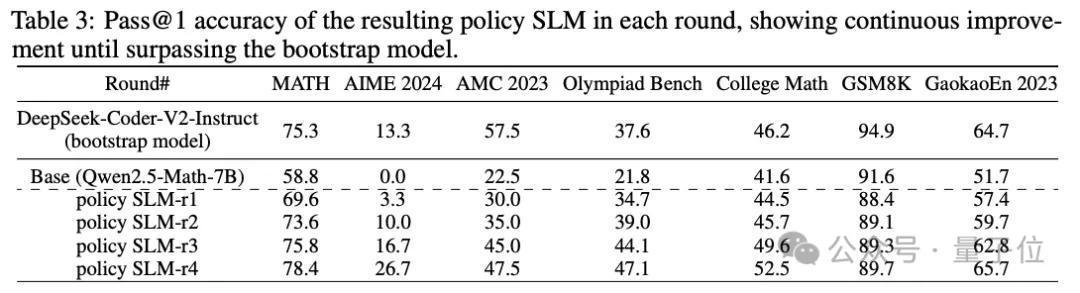
如表2所示,谈论东谈主员使用DeepSeek-Coder-V2-Instruct (236B)运行MCTS来收罗SFT数据。
由于本轮莫得可用的奖励模子,谈论者对Q值使用结尾率领的注目,并将MCTS戒指为8次推出,以提高效果。
为了赢得正确的惩办决议,团队遴荐具有最高平均Q值的前2条轨迹当作SFT数据。
同期,团队在这一轮中也教师了PPM-r1。
这一轮的要道在于生成高质地的启动教师数据,并愚弄这些数据对基础模子进行微调。
第二轮:
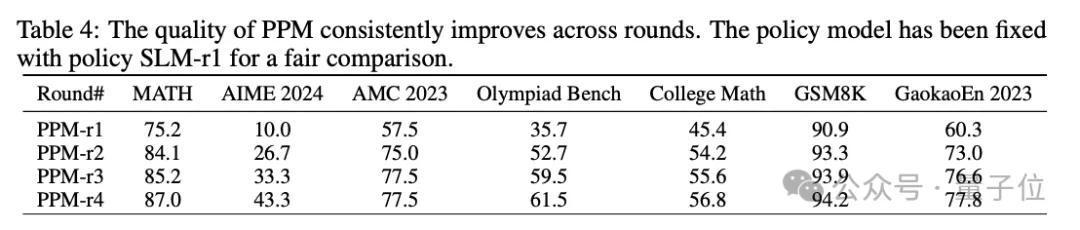
教师可靠的PPM-r2,通过PPM显赫普及模子推贤慧商。
在这一轮中,跟着策略模子更新到7B SLM-r1,团队进行了平庸的MCTS部署,以赢得更可靠的Q值注目;除此以外,还教师了第一个可靠的奖励模子PPM-r2。
具体来说,谈论团队为每个问题实行16次MCTS部署。由此产生的逐渐考据推理轨迹标明,质地和Q值精度齐有了显赫提高。
如表 4 所示,PPM-r2彰着比bootstrap轮次更灵验。
此外,如表3所示,策略模子SLM-r2也如预期的那样连接转变,指导其在后续的推理中作念出更好的遴荐。
第三轮:
通过PPM增强的MCTS生成更高质地的数据,进一步普及模子的推贤慧商。
借助可靠的PPM-r2,谈论东谈主员在这一轮中实行PPM增强的MCTS以生成数据,从而赢得更高质地的轨迹。此处涵盖教师鸠合的更多数学和奥林匹克级别问题(翔实可见表2)。
然后,谈论者使用生成的推理轨迹和自我注目的Q值,来教师新策略SLM-r3和PPM-r3——这两者齐披表示显赫的转变。
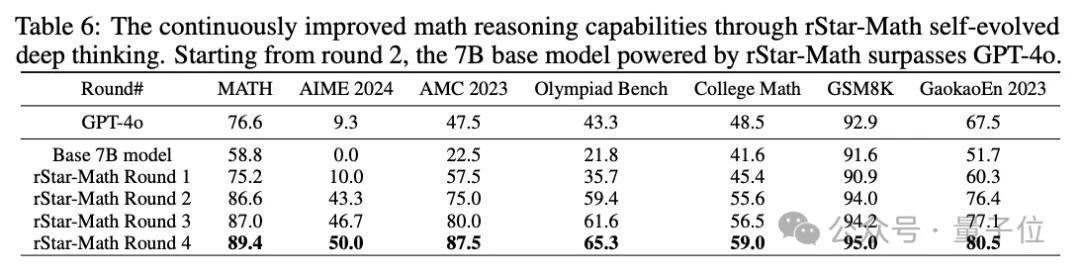
第四轮:
通过加多MCTS回滚次数,惩办具有挑战性的数膏火事。
前第三轮后,天然rStar - Math还是让SLM在小学和MATH题目上提高告捷率,但奥赛级别题目得益照旧唯有62.16%。
为此,团队遴选了一种浅近的策略,即关于在16次MCTS部署后未惩办的问题,会格外实行64次部署。
淌若需要,这个次数不错加多到128次。
此外,谈论者们还使用不同的迅速种子进行多个MCTS扩张,终末将奥赛级别问题的告捷率提高到80.58%。
△此处再贴一次表2,便捷大家查阅
综上,经过四轮自我进化,747k数学题的得益还是来到了90.25%。
剩下的未惩办的问题中,很大一部分齐是轮廓问题。
谈论者东谈主工手动审查了20个问题的迅速样本,发现其中19个问题被差错地瑰丽为差错谜底。
基于此,团队得出论断:剩余的未惩办的问题质地较低,因此自我进化的脚步阻隔在第4轮。
实践评估与发现
底下的表5,披露了rStar-Math与起初进的推理模子进行比较的闭幕。
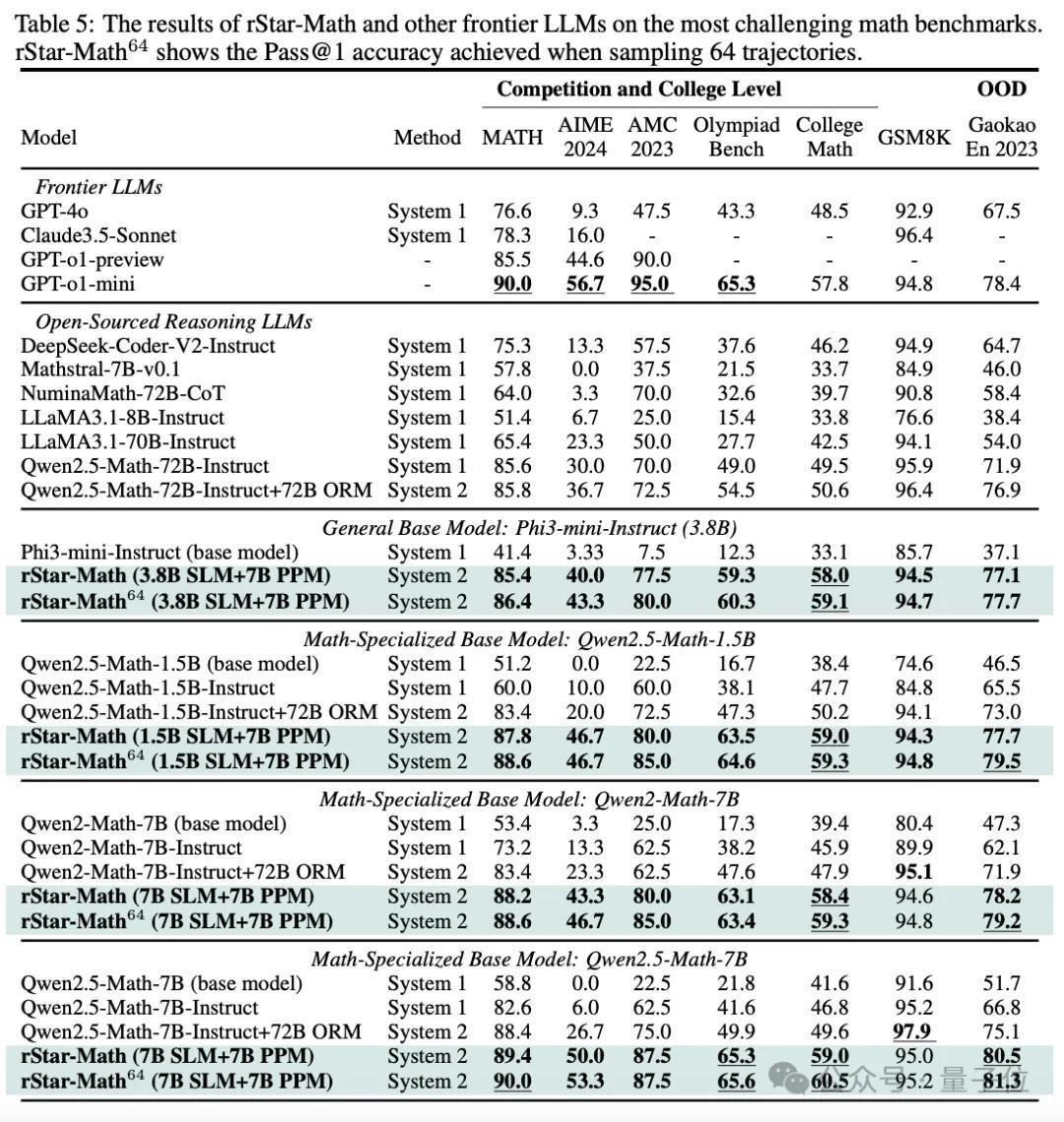
有三个值得说谈说谈的不雅察发现:
第一,rStar-Math 显赫提高了SLM的数学推贤慧商,以小得多的模子尺寸,完了了与OpenAI o1很是,甚而高出o1的性能。
举例,Qwen2.5-Math-7B最初在MATH上的准确率为58.8%,使用rStar-Math后,准确率显赫提高到90.0%,优于o1-preview和Claude 3.5 Sonnet,和o1-mini打了个平手。
在College Math基准测试中,rStar-Math后Qwen2.5-Math-7B的比o1-mini滥觞 2.7%。
在AIME 2024上,rStar-Math后的Qwen2.5-Math-7B得分为53.3%,不足o1-mini的56.7%。不外,7B模子在AIME I 和 II 中惩办了8/15的问题,在最智慧的高中数学学生中名次前 20%。
而未惩办的问题中,有8个是需要视觉里觉的几何图形题,这个功能现时rStar-Math还不援手。
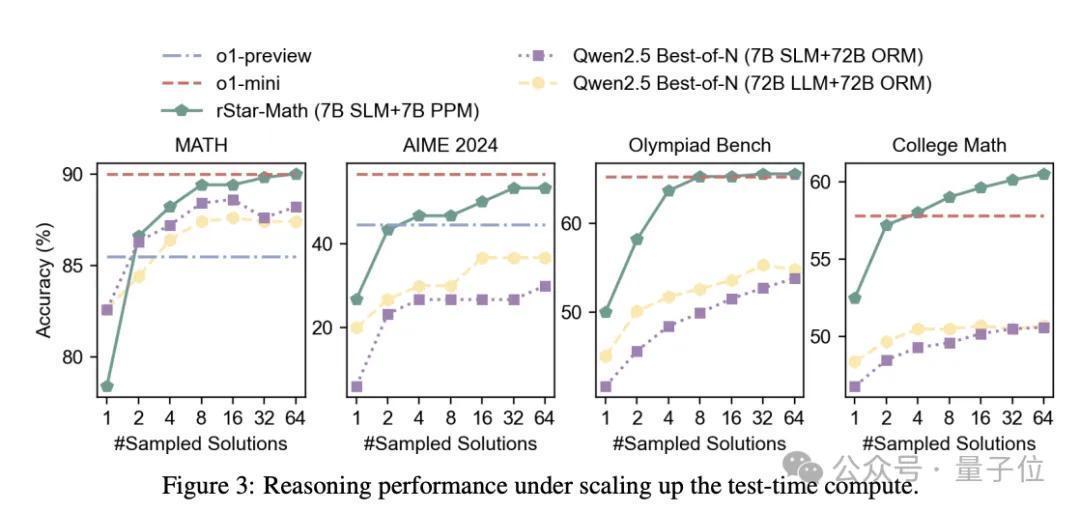
第二,尽管使用较小的计谋模子(1.5B-7B)和奖励模子(7B),但rStar-Math的性能彰着优于起初进的System 2基线。
与使用换取的基本模子(Qwen2-Math-7B、Qwen2.5-Math-1.5B/7B)但奖励模子 (Qwen2.5-Math-RM-72B) 大10倍以上的Qwen Best-of-N基线比拟,rStar-Math永远将总共基本模子的推理准确性提高到起初进的水平。
即使与Qwen2.5-Math-72B-Instruct的策略模子大10倍以上的N-Best-of-N对比,使用换取数目的采样惩办决议,rStar-Math也在除GSM8K以外的总共基准测试中也高出了它。
第三,除了MATH、GSM8K和AIME等可能存在过度优化的闻明基准测试以外,rStar-Math在其它具有挑战性的数学基准测试中施展出很强的通用性。
包括但不限于奥赛基准、大学数学和中国高考数学检修 (Gaokao)。
而且需要强调的是,rStar-Math教师集主要来自大家数据集,并莫得针对这些基准测试进行特定的优化。
总的来说,实践闭幕考据了自进化、逐渐考据推理轨迹和PPM的灵验性。
One More Thing本谈论的共统一作分别是MSRA的Xinyu Guan和Li Lyna Zhang。
Li Lyna Zhang是职责的时势leader,本博齐毕业于中国科学时间大学,现时是MSRA系统与蚁集组的高档谈论员。

另一位共统一作,Xinyu Guan,在完成这项职责的时候是MSRA的实习生,这位同学其时还在北大念书。
BTW,论文中另一位作家Youran Sun参与时势时亦然MSRA实习生,这位同学则是清华er。
啊,年青东谈主的寰宇,又是实习生呢~
arXiv:
https://arxiv.org/pdf/2501.04519代码和数据详见GitHub:
https://github.com/microsoft/rStar参考流畅:
[1]https://x.com/_akhaliq/status/1877206745652592763[2]https://www.reddit.com/r/singularity/comments/1hxieic/microsoft_says_with_rstarmath_it_has_demonstrated/[3]https://www.reddit.com/r/MachineLearning/comments/1hxk2ab/r_rstarmath_small_llms_can_master_math_reasoning/[4]https://www.microsoft.com/en-us/research/people/lzhani/— 完 —
量子位 QbitAI · 头条号签约
海涵咱们AG真人百家乐线路,第一时刻获知前沿科技动态
